Enter Kafka
Apache Kafka was designed to be a publish/subscribe messaging system, it is often described as a distributed commit log or distributed streaming system. A commit log is a sequence of events persisted to disk, which can be read sequentially for replay and rebuild the state of the system. Similarly, messages in Kafka can be read deterministically, in addition, the data can be distributed to provide protection against failures and opportunity for scaling.
The unit of data Kafka work on is message, an array of bytes opaque to Kafka. It can come with an optional metadata called key, which can be used to control which partition the message will be written to. To reduce the number of round trips, messages are often collected as batch before sending to its partition over network. This is a trade-off between latency and throughput, the larger the batch, the larger the throughput, but it increases latency as messages need to wait longer for a complete batch before sending.
Although Kafka does not care about content of the message, it wouldn't be very useful unless we impose some structure on it. JSON is a common human-readable structure, however, it lacks type handling and version compatibility. Many Kafka developer favour Apache Avro, a binary serialization framework, comes with strong data typing and version evolution.
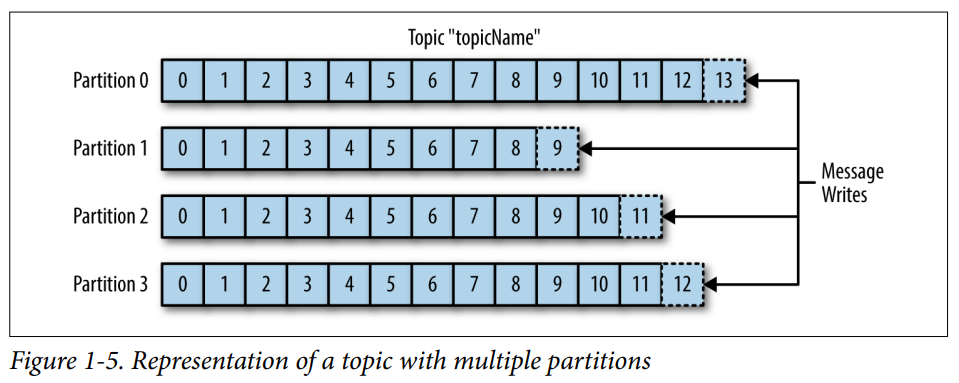
Messages in Kafka are grouped into topics, each message maybe replicated to different partition. During a write, a message is written to multiple partitions. Each partition is essentially an append-only commit log, which is hosted in different servers to provide data redundancy and horizontal scalability.
A key feature of Kafka is durable message, it keeps the message until certain size of the database has reached (e.g. 1GB) or some period of time passed (e.g. 7 days). Topic can be configured as log compacted which only keep the latest message of a certain key.
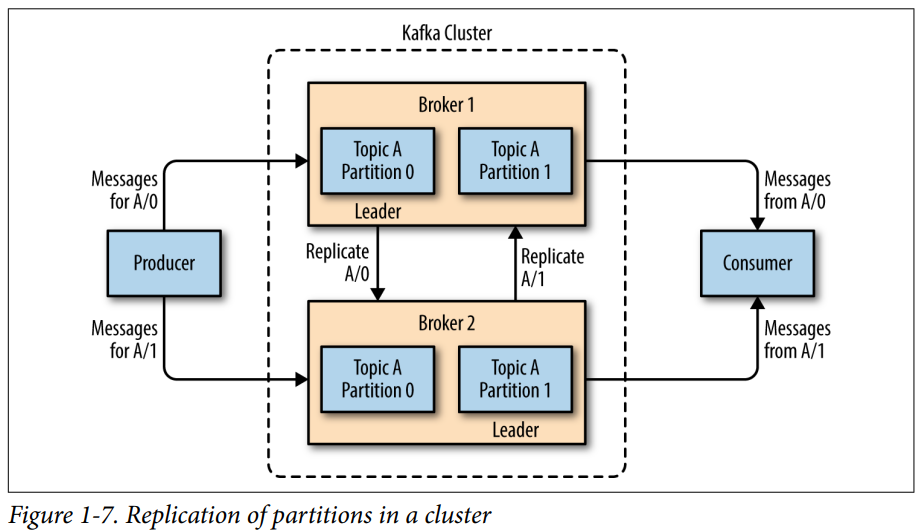
A message is sent from a producer and received by a consumer. Consumers work together as a consumers group, each group ensures each partition is consumed by one consumer. A single Kafka server is called a broker, it receives messages from producers and respond to messages from consumers. Depending on the setup and workload, a single Kafka server can handle thousands of partitions and millions of messages per second.
Kafka brokers are designed to operate within a cluster, within each cluster, one of the brokers is automatically elected as leader, responsible for administrative operations including assign partitions to clusters and cluster replication. A partition maybe assign to multiple brokers, resulting in a replication to provide high availability.
Apache Kafka uses Zookeeper to store metadata about Kafka cluster. A Zookeeper cluster is called an ensemble, it is recommended to use odd number servers (e.g. 3) because a majority of the nodes must be working in order for Zookeeper to respond to requests. It is not recommended to use more than seven nodes, because performance degrade due to nature of the consensus protocol.