Analytics Storage
In the previous blog, we looked at databases from the perspective of implementation, now let's switch gears and look at databases from business perspective. In the early days, databases are created for commercial online transaction processing (OLTP), for example, placing an order, paying salary, making a sale. The access pattern typically involves looking up a specific entry, adding or updating a single record at a time. But as time goes by people started using database for data analytics, which has very different access patterns, it usually involves querying large amount of data with small number of fields, for example, calculating the total amount of sales in a month. Although they are not always a clear-cut, but specialized databases are created separately for this purpose.
Note transaction processing here does not necessarily have the properties of a database transaction in term of ACID. We will talk about these in later blogs.
| Property | Transaction Processing | Data Analytics |
|---|---|---|
| Read Pattern | Small amount of records per query, fetched by key | Large amount of records |
| Write Pattern | Random, low-latency, small writes from user inputs | Bulk imported or event streaming |
| Intended Audience | End user, customer | Business intelligence, decision making |
| Time Range | Latest | Historical |
| Size | GB to TB | TB to PB |
Data Warehouse
For transactional processing, developers optimize database for performance, latency and availability, these factors are critical to keep business running, therefore database maintainers are reluctant to let analytics to run queries on an OLTP database, which can harm concurrent transactions. A data warehouse, in contract is a separated data store optimized for analytics. Data is extracted from the OLTP database either using periodic dump or update streams, without having much effects on its performance. The data is then cleaned-up and transformed into analytic-friendly schema, and loaded into the data warehouse. This process is known as Extract-Transform-Load (ETL).
In the realm of transaction processing there are a variety of data models to choose from, depending on your workload, but in the world of analytics, it is fairly standard, commonly following the star schema (a.k.a. dimensional modelling). It starts with a fact table at its core, each entry typically represents a single event occurred in time for maximum flexibility, containing key metrics you want to analyse, such as sales revenue, order quantities or amount. It is also common to contain foreign key references to other tables (a.k.a. dimension tables) which provide more details, such as information about the retail store where this event took place.
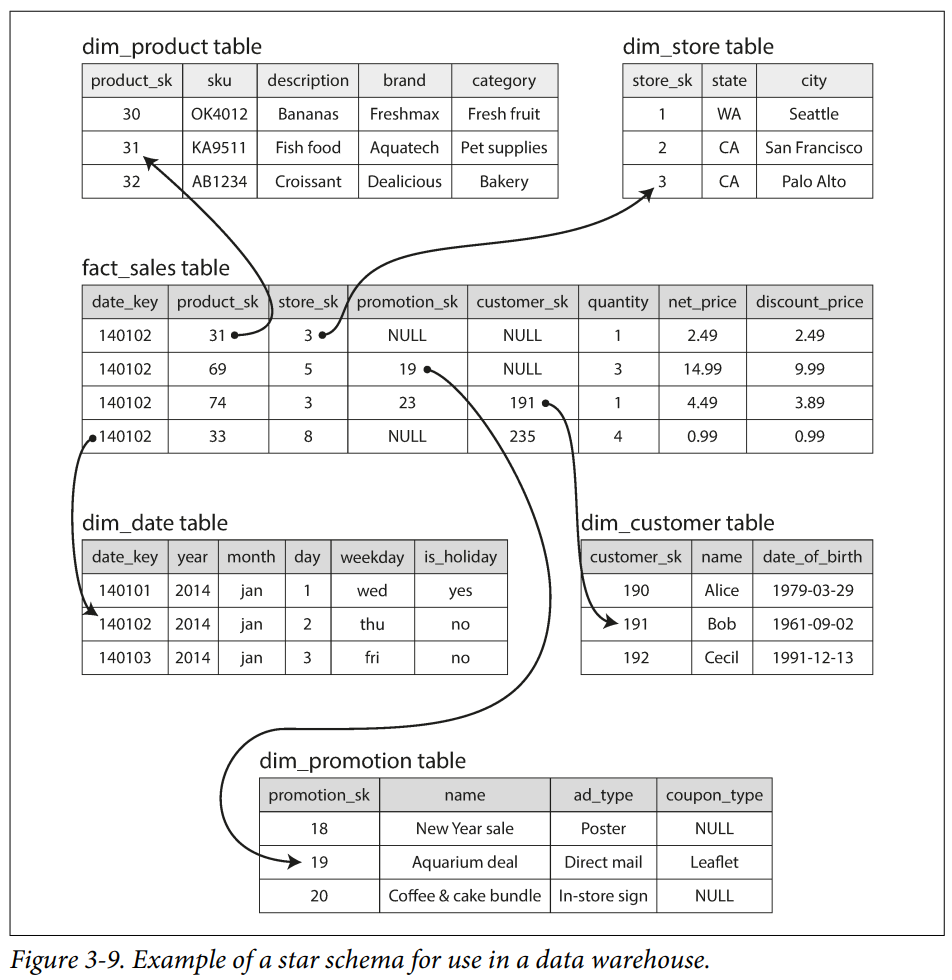
The name star schema comes from how the table relationships are visualized --- a fact table at the middle and supplementary tables around it, like a star shape. A variation of this template is known as snowflake schema, where dimensions are further break down into sub-dimensional, making it more normalized.
Column-oriented
In practice, fact tables can contain trillions of rows with each having over 100 columns. Storing them effectively becomes a challenge. Queries against such table often ask for a large amount of rows with just a few columns. For example, you might want to find the total amount of sales for apple, group by date to see how well apples are selling recently. In a row-oriented storage where each row is stored as a whole, we need to load the whole row into the memory before we can filter by apple. The idea of column-oriented storage is simple, don't store all values of a row together, instead, store all values of a column together. This way we can focus on the columns we are interested in.
Column Compression
One benefit of storing all columns together is to facilitate high compression performance, because values in the same column often comes with similar values. For example, gender has only two values, and country only have 200+ values. We can use a bitmap to encode these values into compact representation and save a lot of space on disk.
Since data warehousing often needs to scan millions of rows, database developers needs to worry about efficiently using bandwidth to load data from disk, avoid branch misprediction, use of single-instruction-multi-data (SIMD) in modern CPUs, and effective use of CPU cycles. For example, a compressed chunk of column data can be loaded into L1 cache, CPU can iterate them in a tight loop (without function call), operators like bitwise AND and OR can operate on these data directly. This is called vectorized processing [ref].
Developers can also choose the sort order of the data depending on the workload, so that similar data is placed together for faster access. A clever extension of this idea was introduced in C-store and adapted in Vertica [ref]. Since different queries can benefit for different sort order, and databases are required to be replicated anyway, we can have different sort order in different replica, so that we can handle more types of queries effectively.
Writing to Column-oriented Storage
The optimization we mentioned made sense for data warehouses, because most operations are read, all the compression and sorting techniques works very well in speeding up reads. But a downside is making writes more difficult. Luckily, LSM-tree we saw is a pretty good solution because its SSTables are immutable, we can use the same approach: writes to an in-memory store first, when enough writes accumulated, merge and flush to disk. Note that b-tree is based on an update-in-place approach, which made it impossible to compress.
Materialized Views
To further improve read speed, you can set up a materialized view. A materialized view is an aggregation of the data warehouse that runs every time a relevant update is made. For example, if your fact table contains individual sale record, you can set up an materialize aggregation to pre-compute sales for each day, output it to another table (a.k.a. materialized view). Several queries that requires sales for each day can directly read from this table instead of aggregating all the entries separately.